The role of public compute
How can we realise the societal benefits of AI with a market-shaping approach?
24 April 2024
Reading time: 12 minutes

We are witnessing a return of something long considered extinct: the strategic state. Across the world, governments are using industrial policy tools to direct the development of important sectors towards societal benefits (for example, the Inflation Reduction Act in the US and the Net-Zero Industry Act in the EU). The AI sector, too, has become the focus of a wide range of national industrial strategies in different jurisdictions, although – as Amba Kak and Sarah Myers West have recently noted – these examples often excise the more progressive elements of modern, democratic industrial policy, such as greater willingness to impose fair conditions on recipients of public money, or to involve workers in determining the pace and direction of technological change.
Compute – the processing power required to train AI models – has become an important vector of these industrial strategies for AI. The UK Government’s £900 million investment in a new UK AI Research Resource (AIRR) aims to provide world-class compute to UK-based researchers, thereby supporting the country’s ambitions to become an ‘AI superpower’.
In the context of a growing compute divide, which has seen access to compute increasingly dominated by a handful of tech companies, investment in public provision of compute is welcome. However, it will not in itself unlock a more plural, public interest model of AI development. This blog post provides an overview of some of the challenges that will need to be addressed if the potential of public compute policies is to be realised.
The growing compute divide
The AI products we use – from general purpose ‘foundation models’ such as GPT-4 to narrowly scoped data analytics systems – operate within a complex supply chain of people, processes and institutions. The diagram below shows how – in the case of foundation models – different inputs, sometimes provided by different companies and institutions, feed into the creation and use of applications like ChatGPT.
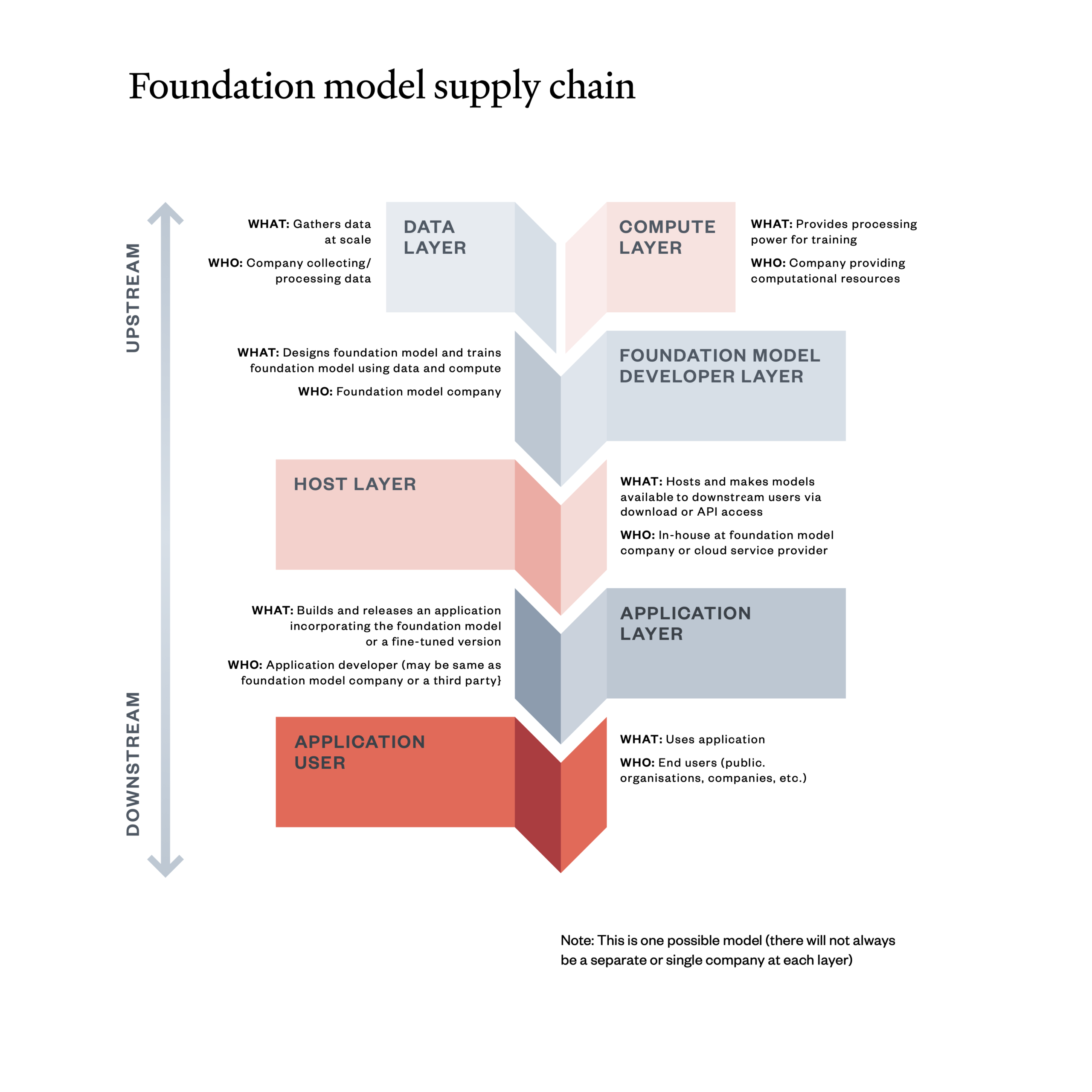
Compute is an important part of this supply chain. Although depicted above as a discrete layer, in practice compute systems comprise a stack of hardware, software and infrastructure components:[1]
- Hardware: chips such as Graphics Processing Units (GPUs), originally used to render graphics in video games but now increasingly applied in AI due to their ability to support complex mathematical computations.
- Software: to manage data and enable the use of chips, and specialised programming languages for optimising chip usage.
- Infrastructure: other physical components of data centres such as cabling, servers and cooling equipment.
The compute needs of large-scale AI models are enormous and have grown rapidly. The largest models today (such as OpenAI’s GPT-4, Google’s Gemini 1.5 and Anthropic’s Claude 3) use 10 billion times more training compute than the largest models in 2010, and the amount of training compute used in the largest models is doubling every five to six months. As the compute intensity of cutting-edge AI research has increased, we’re seeing the emergence of a compute divide. The participation of smaller firms and academic centres in AI research has decreased, with the proportion of large-scale projects run by academics falling from almost 60% a decade ago to almost 0% now in 2024.
The impact of this compute divide is most acute in countries where researchers have only limited access to public compute infrastructure – which is the situation that the UK finds itself in, relative to its peers. The UK possesses only 1.4% of total global supercomputer capacity, ranking 10th in the world behind countries such as Italy, Russia and Finland.
Monopoly control and the public interest
This growing compute divide allows a small number of leading companies, often funded by venture capital, to effectively monopolise AI development, narrowing the diversity of research at the frontier. Venture-capital-funded development needs to provide exponential returns, which pushes towards building winner-takes-all products that can provide significant profits in a short period of time.[2]
The open, non-profit and academic initiatives that continue to operate at the frontier also depend on corporate infrastructure. Organisations and researchers increasingly seek agreements with, or acquisition by, large companies that operate their own compute facilities: consider the partnerships struck by OpenAI and Mistral with Microsoft, or the increased prevalence of collaborations between academia and industry. The effective consequence of this is that the existing paradigm of AI development, even in its ‘open’ and academic instantiations, is led by and wholly dependent on funding and infrastructures provided by Silicon Valley.
This has implications for the future of public interest AI. Many have argued that such a concept is a contradiction in terms: that the development practices of modern AI are too ecologically destructive, and the possible applications too closely bound up with harms such as misinformation, exploitation and over-surveillance. Whether or not this is the case, it is, however, abundantly clear that governments cannot rely on the good grace of private companies to provide compute infrastructure for use cases that may be publicly beneficial but not commercially profitable. This is not to deny that private sector AI development has helped to advance the public good in specific ways: Google DeepMind’s open source release of Alphafold is a good example of a frontier AI project supporting scientific discovery. That project, however, is a relic of the company’s former role as a research company and not its current trajectory as an in-house developer for Google’s commercial AI products.
The case for public compute
On current projections, the gulf between the UK’s compute availability and the growing compute needs of UK researchers will continue to expand. In practice, this would mean cementing the dominant position of commercial providers of cloud compute: the scale of capital investment required to break into this highly consolidated market would be beyond the resources available to most individual UK companies. Investing in high-quality, accessible compute infrastructure is therefore vital if the UK is to cultivate a vibrant and diverse AI ecosystem that is responsive to wider societal challenges rather than the profit imperatives of the AI industry.
The public sector is effectively placed to deliver this infrastructural development: it has higher risk-bearing and coordinating capacity than private investors and comparatively lower borrowing costs to undertake large-scale and long-term investment programmes. There is therefore growing recognition that the UK’s public compute capabilities should be upgraded as a national priority, as stated in the Independent Review on the Future of Compute.
This is in line with trends in other countries: France, for instance, is investing significant sums in public compute, while the establishment of a National AI Research Resource (NAIR) remains a long-term bipartisan policy goal in the USA.
Despite this enthusiasm, questions remain around cost and feasibility. Public capital expenditure is currently circumscribed by tight fiscal, infrastructural and ecological limits, which risk curtailing ambitions on public compute. While some of these limits are self-imposed in the form of fiscal rules, others – such as the paucity of UK sites with sufficient water supply and grid capacity to host compute infrastructure – will be harder to surmount without reforms to the planning system and public investment in sustainable water and energy infrastructure, and while remaining within the UK’s legally-binding climate targets.
The proposed timescale of public compute investments has also been called into question, given the extensive – albeit easing – wait times for the most advanced hardware, coupled with the public sector’s relative lack of agility in procurement when set next to the big tech firms with which it would be competing.
Moving beyond an ‘arms race’ narrative
If public investment in compute is to truly support public interest AI development, it needs to be framed in the right way. As we have recently argued, investments in AI are often justified with recourse to an ‘arms race’ narrative that obscures the ways that AI policy can be used to shape and redirect AI development.
Our contention is that public compute investments should instead be seen as an industrial policy lever for fundamentally reshaping the dynamics of AI development and therefore the direction of travel of the entire sector. The aim of these policies should not simply be to build more and faster, but to challenge concentrated power and promote the creation of public value throughout the AI supply chain. Realising this goal will mean grappling with several challenges, which we outline below.
Challenge 1: What does ‘public benefit’ look like and how will public investment in compute resources help to deliver it?
Politicians and industry frequently invoke the promise of AI: from scientific discovery and better public services to tackling climate change. Yet as alluded to above, genuine public benefit from AI remains elusive and difficult to measure.
There is a need to be more precise – and more critical – about what is meant by ‘public benefit’ from AI, and what barriers and dependencies need to be addressed to deliver it. Governments invest in sectors like renewable energies because they produce things we want, while satisfying other policy aims such as job creation. The equivalent case for industrial investments in AI remains unclear, and without it there is a risk that investments in AI will simply reinforce the dynamics described above of concentration and corporate capture.
Challenge 2: How should public compute resources be governed and who should be able to access them?
The Future of Compute Review recommended the establishment of a dedicated AI Research Resource (AIRR), which the UK Government has subsequently confirmed will be hosted by the University of Bristol.
Governance of AIRR should centre the perspectives of users and other relevant stakeholders (including researchers, small and medium-sized enterprises and frontline professionals in sectors where AI benefits are posited and communities are impacted by AI). Mechanisms for ensuring this could include board seats and mandatory public engagement exercises.
AIRR should adopt an expansive understanding of AI research, prioritising a mix of public interest projects and AI safety research, in addition to commercially viable projects developed by universities and accredited researchers from the private, public and third sectors.
AIRR could also impose conditions on users of public compute, such as:
- obligations around safety (for example, model access, third-party auditing, documentation requirements)
- contribution to a public digital commons (providing open or structured access to models or data for other AIRR users)
- commitments to reduce compute usage over time by improving efficiency (for example, prioritising algorithms that use less compute for the same output)
- governance and ownership obligations, including, when appropriate, the option of a public stake in organisations set up to commercialise or institutionalise research.
In this manner, the allocation of public compute through the AIRR could promote certain AI activities – those that are more likely to be safe, sustainable and socially beneficial – while disincentivising others.
Challenge 3: How can the UK Government balance meeting immediate demand with building greater public capacity?
In the short term, AIRR could use commercial cloud services to rapidly meet existing demand. Leveraging the buying power of the UK Government could make bulk purchases of cloud credits cheaper than individual companies buying alone.
However, relying on existing providers for cloud capacity and GPUs creates other policy challenges. The AI Now Institute and Data & Society have argued that this approach, as proposed in the context of the USA’s NAIR, risks entrenching public dependency on large incumbent firms.
The UK Government could therefore set longer-term targets for onshoring the different stages of the compute supply chain, with the aim of building diverse domestic (including public) capacity.
These targets would need to be realistic – the supply chain for compute is highly globalised and no country has succeeded in achieving full self-sufficiency, despite concerted attempts – but some increase in the UK’s domestic capacity for chip design and cloud provision could be feasible. This could be complemented by a ‘friendshoring’ approach that would prioritise goods and services located in countries with industrial and environmental approaches aligned to the UK’s own.
Challenge 4: What mix of other ‘market-shaping’ industrial policy interventions should the UK Government use alongside the AIRR?
Public compute policies should be coupled with a wider suite of industrial policy measures to help steer the AI market. This might include, for example, pro-competitive measures like banning or disincentivising vertical integration (for example, companies that provide cloud infrastructure developing their own chips). It could also involve treating computing providers as public utilities, which would involve ensuring they treat all customers fairly and do not make it difficult to switch between providers.
Other market-directing policies could also include investments in monitoring infrastructure to better understand trends in the research, development and deployment of AI. At present, the UK Government is largely reliant on industry expertise for these insights, with the risk that policy is over-optimised for the needs and perspectives of incumbent companies.
Finally, public compute investments could be complemented by investments elsewhere in the AI ‘stack’. For example, the public sector could facilitate the development of AI models and applications that are not currently well-served by market trends: public-service recommendation algorithms, for instance, or data analytics solutions optimised to the needs of local authorities. It could also pilot new institutions at the data layer – from data co-ops to a ‘BBC for data’ – to address the current dominance of data infrastructure by big tech.
Conclusion: defining the AI public benefit
Leaving the pace and direction of AI development wholly to market forces will fail to realise its full benefits. Expanding public compute is one way of exerting greater public control over the AI sector, and in doing so helping to ensure it develops towards the benefit of people and society.
Achieving this will mean thinking more precisely about what ‘public benefit from AI’ means: articulating a vision of AI that links its functioning in the UK economy to a wider vision about the society we want to live in. So far, such a vision has been lacking – but if it can be developed, it will in turn furnish us with answers about which infrastructures we should prioritise, and how compute procurement could help create value for people and society.
The case for action is clear, and the need for clarity of thinking urgent.
The authors would like to thank Amba Kak, Andrew Strait, Connor Dunlop, Elliot Jones, Fran Bennett, Michael Birtwistle, Octavia Reeve, Sarah Myers West and Valentina Pavel for comments on an earlier draft of this piece.
[1] This description of the compute ‘stack’ is adapted from Jai Vipra and Sarah Myers West “Computational Power and AI,” AI Now Institute, September 27, 2023, https://ainowinstitute.org/publication/policy/compute-and-ai
[2] The extent to which this holds varies significantly by company: Google Deepmind, for example, faces different commercial pressures to OpenAI or Anthropic.
Related content

Seizing the ‘AI moment’: making a success of the AI Safety Summit
Reaching consensus at the AI Safety Summit will not be easy – so what can the Government do to improve its chances of success?

Regulating AI in the UK: three tests for the Government’s plans
Will the proposed regulatory framework for artificial intelligence enable benefits and protect people from harm?
Data, Compute, Labour
The monopolisation of AI is not just – or even primarily – a data issue.