Tokenising culture: causes and consequences of cultural misalignment in large language models
How do AI systems embed cultural values and what risks does this imply?
19 June 2025
Reading time: 14 minutes

Say you programme a robot to make you a cup of tea. You send the agentic system to complete its task and find broken drawers, shattered cupboard doors and boiling water all over the kitchen floor, alongside your cup of tea. This example is commonly used to explain the alignment problem: the notion that, when programming a system, one must define not only the desired goal, but also the undesired ways to achieve it.
The issue has gained popularity, particularly with the development of large language models (LLMs) and agentic AI assistants, with many considering it the most pressing problem of our time, alongside the risk of nuclear war or global pandemics.
The tea analogy reflects the AI community’s emphasis on tangible harms from misaligned systems and its present research focus on problems such as user manipulation, reward-hacking and power-seeking.
Little attention is instead given to what values LLMs may reflect and what behaviours they may assume beyond those relating to safety. How well do the values, beliefs and behaviours of these models align with those of their users?
While not as tangible as broken doors and drawers, the asymmetrical cultural alignment of LLMs with different groups of people may carry profound societal consequences.
Whose values do language models reflect?
When we interact with LLMs, such as through AI assistants, whether to ask for professional advice or proofread a text, they reflect specific viewpoints and cultural values. Given their intended uses, this is in some ways inevitable: without implicit beliefs and worldviews, the functionality of these models would be mostly restricted to objective queries like spell-checking, mathematics and information retrieval.
The cultural alignment of LLMs has been measured in various ways, with the most common being comparing systems’ responses to the results of existing cross-national surveys, like the World Values Survey, which include multiple choice questions on politics, religion, family, society, national pride etc.
This closed method of assessment has been under increasing methodological and conceptual scrutiny, given its sensitivity to prompt design and generalisation of the values people from the same country supposedly hold. However, it offers a way to visualise and understand the current state of cultural alignment and makes an obvious question unavoidable: whose values do language models represent?
Research seems to suggest that leading LLMs today, from firms such as Anthropic, Meta, OpenAI and Google, most closely represent the values of people in the USA, and other countries1 whose cultural profile is often described with attributes like Western, educated, industrialised, rich and democratic (WEIRD) .
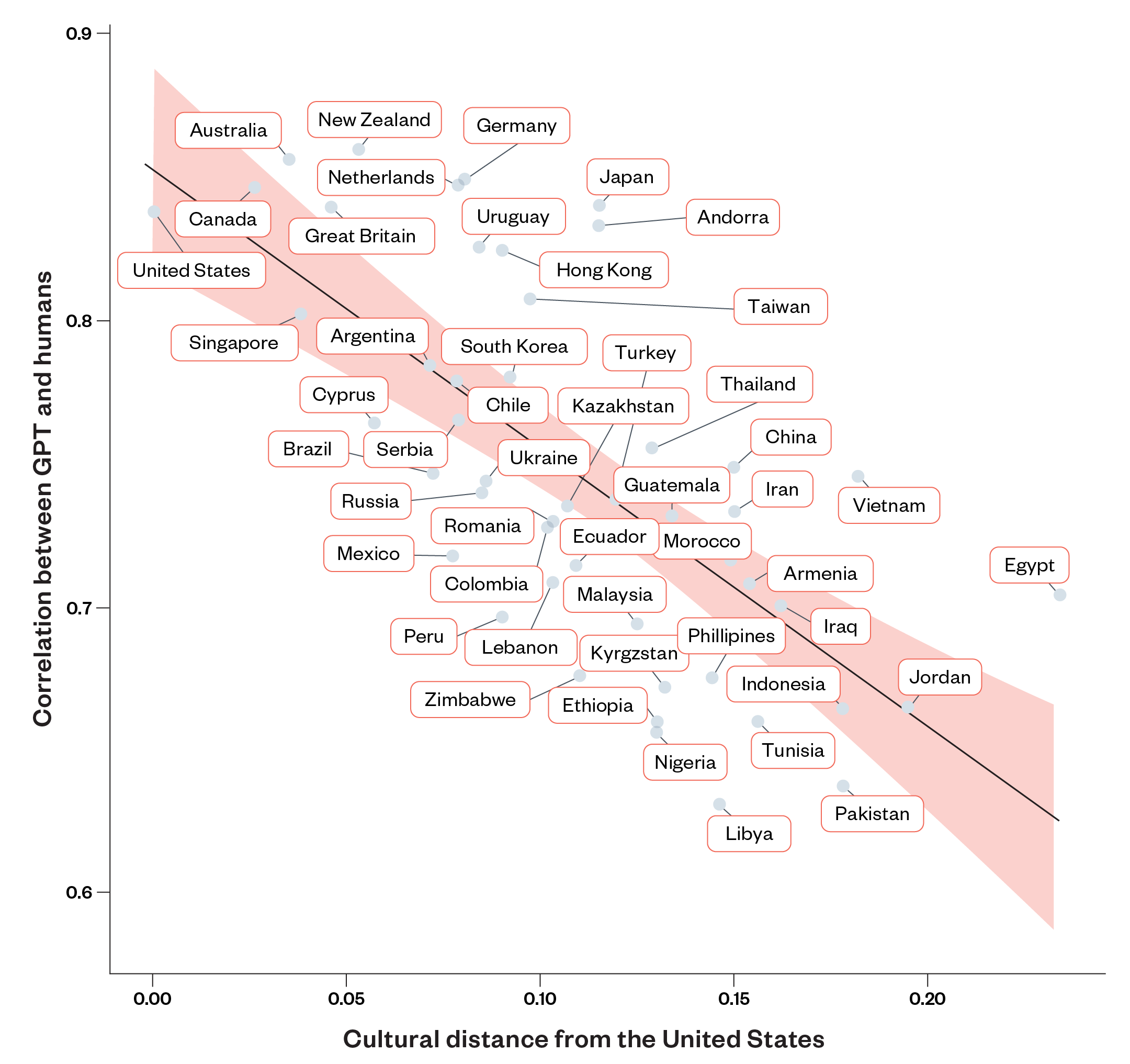
Figure 1 offers a visual representation of this: as the ‘cultural distance’ (as referred to in cultural psychology) of a country from the USA increases, the similarity of GPTs survey responses to those collected in the country decreases. While GPT’s replies strongly resemble the opinions of people living in Australia, Canada and the United Kingdom, for example, they weakly represent those of people living in Jordan, Pakistan and Libya.
Figure 1: The scatterplot and correlation between the magnitude of GPT human similarity and cultural distance from the United States as a highly WEIRD [Western, educated, industrialised and democratic] point of reference (source: PsyArXiv Preprints | Which Humans?)
This bias appears also in the behaviours LLMs exhibit during user interaction. Examples of this include their prioritisation of individualism, and default assumption of Anglo-Saxon norms.
The reinforcement of dominant norms
As of late February 2025, OpenAI had registered 400 million unique users, around 5% of the world population. As more and more people rely on its products and similar systems for advisory and interlocutory functions (e.g. legal advice, professional counselling and companionship), the values these LLMs have embedded could increasingly affect how users interact with and perceive the world around them, and in ways that might be at odds with their values.
Politically, this could lead to novel forms of digital cultural hegemony.
The cultural compatibility gap
With every new development of LLMs come promises of individual and societal benefits, from efficiency gains, educational opportunities, productivity increases and everlasting companionship, to economic transformation and operational streamlining.
Beyond infrastructural, economic, financial and societal boundaries, which may prevent this from coming to fruition, value biases of LLMs introduce yet another hurdle: cultural compatibility.
How can we expect these systems to work equally well with different communities, regardless of their opinions, when their values are only aligned with a narrow set of nations?
Take the mental healthcare sector. Usage and interest in therapy chatbots is growing in several countries.2
The concept of culturally competent therapy is a cornerstone of therapeutic training.3 Abundant research demonstrates how cultural norms can shape attitudes towards depression4, pain normalisation and anxiety, and the impacts that different cultures can have on a patient’s mental health.
Cross-cultural differences have been formally acknowledged through regulatory restrictions. Cultural, legal and ethical standards in healthcare vary significantly between jurisdictions and each country (and in some cases, regions within a country) requires clinical therapists to obtain specific licenses to practice.
If human therapists can’t practice across borders without adapting to local norms, why should we expect AI systems trained predominantly in one cultural context to serve everyone and everywhere with equal effectiveness?
This is not unique to healthcare. The implementation of AI tutors in education may benefit students, but only depending on how aligned the systems are with their mannerisms and expressions, and with local pedagogical approaches.
The consequences of cultural incompatibility are exacerbated in countries with tighter government budgets and pressing challenges, where investments in LLMs may come with significant opportunity costs.
Why language models have a cultural value bias
Cultural value biases can be traced down to three elements:
- The algorithmic monoculture in the LLMs marketplace
- The data that they’re trained on
- The post-training fine-tuning methods.
Algorithmic monoculture
While the LLM marketplace has yet to produce a ‘Google’ equivalent with almost 90% of market dominance, most users worldwide rely on a handful of models developed by a small number of companies unsurprisingly based in Western Europe and the USA.
In large part, this is due to the monopoly-like structure of the frontier LLM market, in which firms must be ready to lose large amounts of resources and can rip benefits and reduce costs only when they scale up investments. These dynamics reinforce the dominance of few corporations, and raise the entry barrier for global competitors.
The one-to-many market structure of frontier LLMs leads to what can be described as algorithmic monoculture, where a handful of models serve a wide range of users across the world.
At a micro level, there might be several reasons why we got here. First, producing value-variant models is complicated compared to creating one ‘global’ model. Models overrepresent Western European and American mainstream values for a reason: it’s the easiest thing to do. All the while, first-mover market incentives and rapid scaling pressures favour quick deployment and rollouts, further deterring firms from investing in and deploying value-variant models.
At a macro level, the concentration of tech talent, investment and expertise in tech hubs, such as California’s Bay Area, means that a few firms shape the industry’s priorities. If they ignore cultural alignment, others will likely do the same.
Training data
To process texts, LLMs break down words into tokens. For example, the English idiom ‘it’s raining cats and dogs’, would be split as:

The relationships between these tokens can change drastically depending on how training data represents a language. For example, we might expect ‘cats’ and ‘dogs’ to be more closely clustered to ‘rain’ in English-based language models than language models trained on Spanish text (see Figure 2).
Figure 2: comparison between tokens’ relations in LLMs trained with English language datasets and Spanish language datasets. The graphic combines data from two separately trained models, which exist in different mathematical spaces. This visualisation should be seen as an illustrative demonstration rather than a rigorous comparison.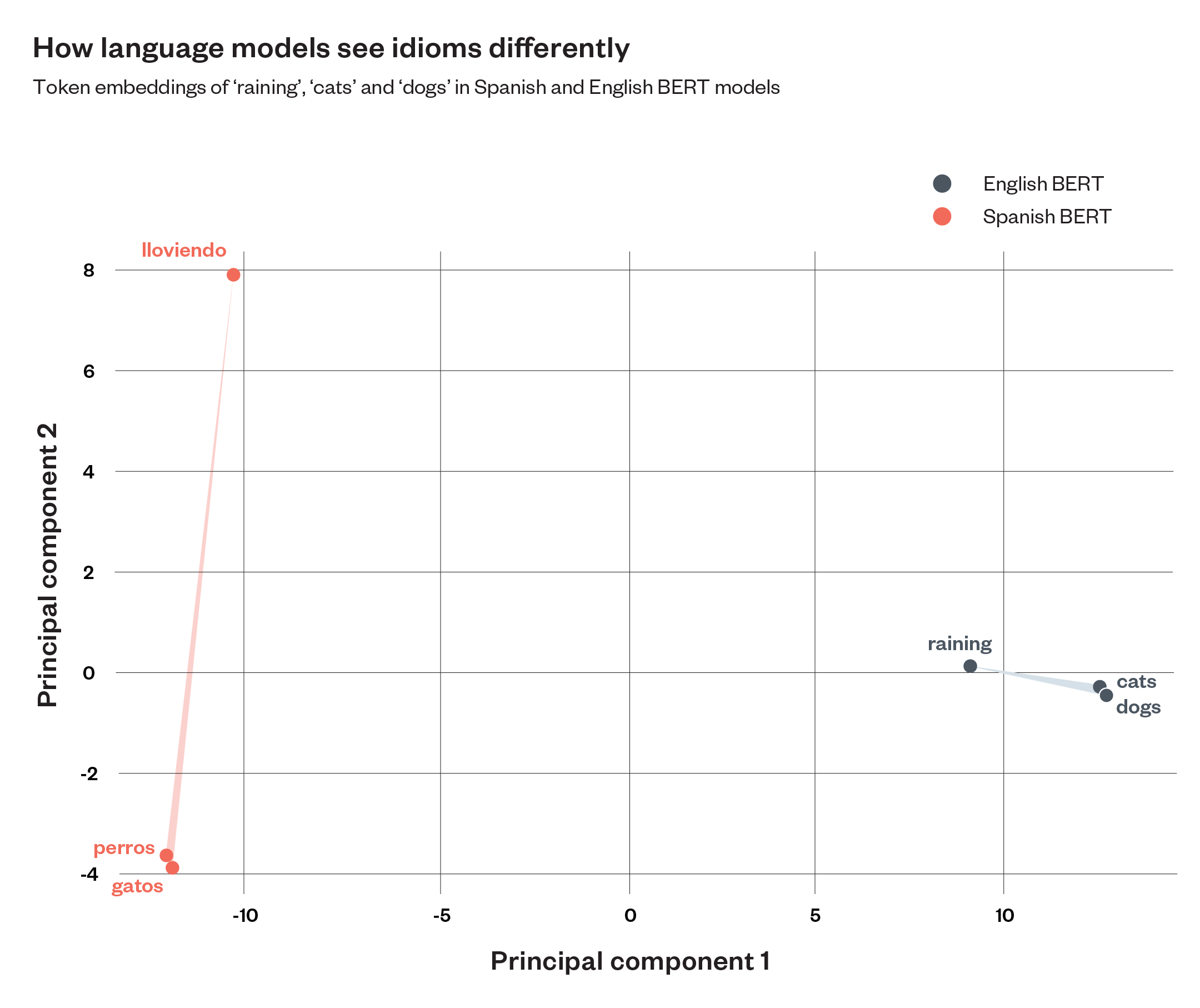
The ‘distances’ between tokens affect the possible answers models give to queries and, as a result, the values, opinions and beliefs they reflect. Just as English models are more likely to understand and use the idiom ‘raining cats and dogs’ because those tokens are closely linked in their training data, they’re also more likely to express cultural concepts, sayings, and values that are common in English text.
To ensure that models embody culturally representative values, their training data must be in languages that reflect these values.
However, with around half of the content on the internet in English, if frontier models are trained on publicly used datasets like web data repository Common Crawl, their training data will predominantly consist of English text. And as models are trained on datascraped online, who in a country uses the internet will ultimately shape a system’s behaviour.
As of 2022, around 97% of Americans were reported to have used the internet in the last 3 months. We find similarly high percentages in, for example, Australia (95%), Spain (94%), Norway (99%), and South Korea (97.17%). Unsurprisingly, these numbers dwindle in less economically prosperous countries, such as Sudan (28.7%), and Indonesia (67%).
In the countries with the lowest percentage of active internet users, we may also expect these to be less representative of the wider population at an economic, demographic and social level. For example, it’s unlikely that the 28.7% of Sudanese population with internet access is representative of the beliefs and values of many, if not most, of the people living in Sudan.
Post-training methods
The internet is full of dangerous, harmful, mendacious and oftentimes violent content. LLMs trained on online data inevitably absorb both the good and the bad. To make these models safer and more aligned with user values, AI labs use post-training methods like Reinforcement Learning from Human Feedback (RLHF) – a process where human annotators rate model responses, guiding its behaviour through reinforcement learning.
Who the people involved are shapes the feedback the model gets. If the majority of RLHF workers come from American backgrounds, the model will tend to adopt cultural values that are popular in the USA.
In many cases RLHF participants (often sourced from crowd-working platforms like MTurk) are predominantly English-speaking, US-based, between 25-35 years old and hold a master’s degree. Often fewer than 100 individuals shape language model behaviours, which means that a small subset of cultural values will continue to be prioritised and reinforced.5
Towards cultural alignment in LLMs
There are several actionable steps we can take to steer AI development towards greater cultural alignment. Raising awareness of the problem could incentivise developers to measure, learn and mitigate cultural value biases in language models. Importantly, this could advance the field beyond closed, survey-based and unduly generalised cultural alignment benchmarks.
All the while, greater investment towards low-resource language models, or multilingual models, tailored to the needs of linguistic groups could create a more value-variant marketplace for LLMs. Notwithstanding growing concerns for the deteriorating performance of multilingual models, initiatives to collect more multilingual data from diverse places, such as Cohere’s Aya dataset, remain a step in the right direction.
Reporting standards, whereby developers provide in-depth details of the development process of a model, can also play a crucial role in fostering cultural alignment. Enforcing more transparent and detailed reporting on AI development processes – such as the demographic makeup of RLHF evaluators – may contribute to a more robust, diverse, and representative participation in model production.
In systemic terms, greater cultural alignment in language models may be constrained by the current centralisation of the LLM market. Financial incentives are unlikely to push firms toward creating more culturally diverse and value-aligned models, especially given the intangible nature of such benefits.
While the LLM landscape has recently seen some geographic diversification, with releases like DeepSeek’s R1, Qwen, and others, these examples don’t necessarily indicate a broader shift toward decentralisation, as they are shaped by China’s unique economic and technological environment. Nonetheless, they do reflect a promising trend towards increased efficiency and cost-effectiveness in LLM development. This could lower model’s production costs, enabling smaller, more culturally diverse players to enter the market. In similar vein, while the societal and market implications of open source foundation models remain a contentious topic, it could be beneficial from the lens of cultural alignment. Public access to weights, data and developmental details of frontier models could lower the entry barrier for smaller developers from underrepresented backgrounds, thus promoting a more diverse and richer marketplace.
Any step towards greater cultural alignment, however, does come with a caveat: while the actions to take may seem clear, the desired outcome is harder to imagine. How many value-variant models will we need? Beyond the training data, how do we decide what values societies with low digital footprints have?
The deeper we dig, the more layers emerge: each culture fracturing into societies, countries, cities, neighbourhoods and ever-smaller clusters, making true cultural alignment an endlessly receding horizon. It might be intuitive to land on the prospect of hyper-personalised language models, trained on individual user data to adapt to their beliefs. At this intersection, however, lie greater questions on information ecosystems, echo chambers, autonomy, and even consumer demand.
- For sources see: Yan Tao et al., ‘Cultural Bias and Cultural Alignment of Large Language Models’, PNAS Nexus 3, no. 9 (1 September 2024): pgae346, https://doi.org/10.1093/pnasnexus/pgae346; Mohammad Atari et al., ‘Which Humans?’ (OSF, 22 September 2023), https://doi.org/10.31234/osf.io/5b26t; Nicholas Sukiennik et al., ‘An Evaluation of Cultural Value Alignment in LLM’ (arXiv, 11 April 2025), https://doi.org/10.48550/arXiv.2504.08863; Rebecca L. Johnson et al., ‘The Ghost in the Machine Has an American Accent: Value Conflict in GPT-3’ (arXiv, 15 March 2022), https://doi.org/10.48550/arXiv.2203.07785.
- In a recent poll conducted by Oliver Wyman in India, around 51% of survey respondents expressed a willingness to use AI-generated therapy. ‘How AI Could Help Improve Access to Mental Health Treatment’, World Economic Forum, 31 October 2024, https://www.weforum.org/stories/2024/10/how-ai-could-expand-and-improve-access-to-mental-health-treatment/.
- For references, see: ‘Training :: NHS North Kensington Major Incident Response’, accessed 24 April 2025, https://www.grenfell.nhs.uk/cultural-competence/training; Wendy Chu, Guillermo Wippold, and Kimberly D. Becker, ‘A Systematic Review of Cultural Competence Trainings for Mental Health Providers’, Professional Psychology, Research and Practice 53, no. 4 (August 2022): 362–71, https://doi.org/10.1037/pro0000469.
- Ian H. Gotlib and Constance L. Hammen, Handbook of Depression, Second Edition (Guilford Press, 2008).
- For references, see: Hannah Rose Kirk et al., ‘The Past, Present and Better Future of Feedback Learning in Large Language Models for Subjective Human Preferences and Values’, in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, ed. Houda Bouamor, Juan Pino, and Kalika Bali (EMNLP 2023, Singapore: Association for Computational Linguistics, 2023), 2409–30, https://doi.org/10.18653/v1/2023.emnlp-main.148.
Related content

Now you are speaking my language: why minoritised LLMs matter
How to ensure AI systems in 'low-resource' languages thrive
Delegation Nation
Advanced AI Assistants and why they matter

AI assistants
Helpful or full of hype?